Azure Data Factory is a cloud based tool for data movement and transformations. A little more than a year ago a new feature, Data flows, was published which made it possible to do data manipulations and transformations without coding: User can drag and drop components into canvas to build processes to move and transform data. There are different kind of components available for manipulating data like filter, pivot, aggregate and lookup. It’s a pretty nifty tool for a lazy data engineer. Here’s a picture of a Data flow which loads customer data into a Data Vault 2.0 modeled data warehouse:
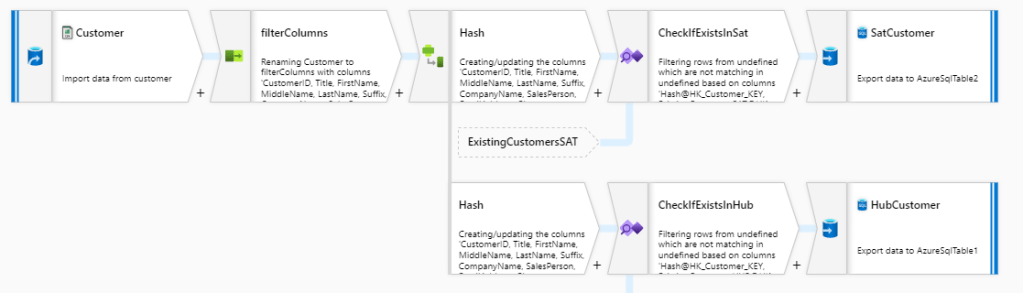
Data flows are collected into pipelines which are a logical group of different activities. These together perform data manipulations. Under the hood Data flows are compiled and run on an Apache Spark cluster. According the documentation, pricing is based on three categories:
- Type of compute
- Number of cores in cluster
- Running time
There are three different options for compute type to choose from:
- General purpose: Default option and good for most workloads
- Memory optimized for flows which have lots of lookups and joins (needs more memory)
- Compute optimized for simple transformations
Cluster size can be configured while provisioning the runtime and minimum setup is 8 cores (16 for memory optimized). Here’s a list of available values for General purpose compute type:
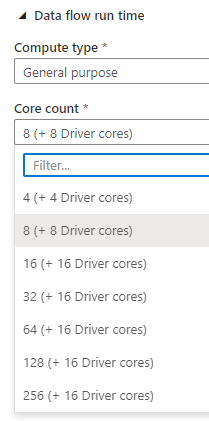
At the time of writing (January 2021), the prices for different compute types in West Europe region are:

So if we have a Spark cluster which is of type General purpose, # of cores is 8 and we run it for one full hour, total cost will be 0,227€ * 8 = 1,816€. Pretty straightforward but let’s do test it anyway!
I created a dummy Data flow which connects to a Azure SQL database, aggregates data and saves result into database:

Then I set up a pipeline which ran this Data flow two times in a row. Don’t try to figure out the business logic of this ’cause there isn’t one: this is totally made up just to test the billing part:

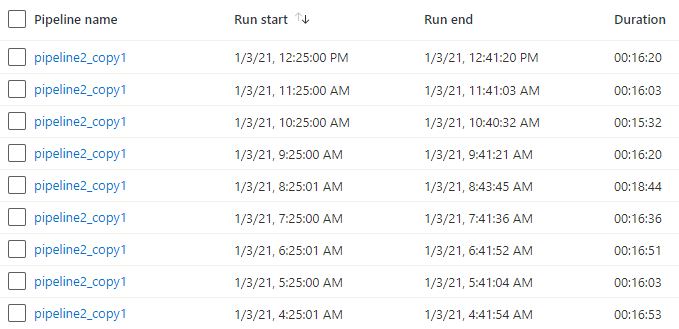
A trigger ran this pipeline once in an hour for one day. Here’s a screenshot of monitoring view which shows couple of those runs. Interesting part from billing perspective is Duration column which tells us that the pipeline took approx. 16 minutes to finish:
Consumption details for each run can be viewed by pressing Consumption icon:

Details for the one above are here:

We can see that it took 2.0495 vCore hours to run. Where does this number come from? My runtime was a type of General purpose and had 8 cores in it. Total duration was 16 minutes which is about 0.2667 hours. And we had 8 cores so the total vCore-hours is 8 * 0.2667 which makes about 2.1. Quite close compared to 2.0495 shown above. There’s always some overhead in form of spinning up the cluster so actual run time of cluster is little less than total duration of pipeline. Price for this one run would be 2.0495 * 0.227€ which makes 0.47€.
In total pipeline ran 25 times. I went through those all and added vCore hours together and came up with a total of 52.0138. So the actual cost was 52.0138 * 0.227€ which makes 11.81€.
So far everything has been just a theory. How about reality? I mean what is the actual amount I’ll see in my bill? I was curious to see how this would look like so I jumped into Azure portal billing section. Here’s the result:
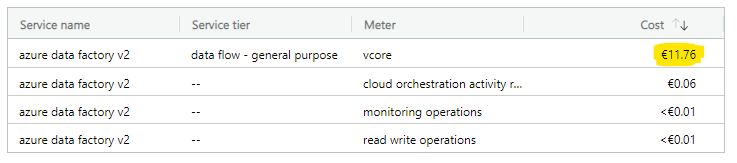
It shows 11.76€ so close enough compared to that 11.81€: Theory seems to work!
One thing to note in the billing data is the line cloud orchestration activity run which has a cost of 0.06€. Based on Data Factory billing documentation those refer to activity runs, trigger executions, and debug runs. Billing is based to number of these activities and price quite cheap: Less than 1€ for thousand activities:

So where does that 0.06€ in my bill come from? Let’s take a closer look at the picture of consumption details:

It has a row for Pipeline orchestration with an entry for Activity Runs and number two on it. Remember that in pipeline had two activities in it which both ran the same Data flow. That’s the reason for 2 activity runs. Pipeline was executed 25 times so number of activity runs is 25 * 2 = 50. Also all trigger executions must be added and there were 25 of those so the total number of activity runs in this case is 50 + 25 = 75. Now if we calculate the total amount, we will end up with figure 75/1000 * 0.844€ = 0.0633€. Once again close enough!
Conclusions
Data flow billing is quite straightforward and two main factors of cost are running time and size of the Spark cluster. There’s also some other things to be included but those are typically just a fraction compared to those two main factors.
