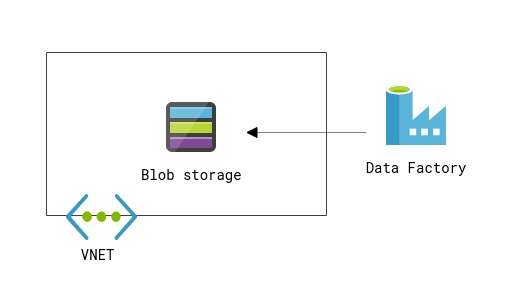
Microsoft’s cloud ETL service, Azure Data Factory (ADF), has been in general availability for good time already. It’s a serverless platform for transforming and moving data between different kind of on-premise and cloud services. About year ago I was working as an architect in a project where we utilized ADF to move data into a blob storage. We had our blob attached to a VNET which means it was isolated from public network, effectively behind a firewall. VNET is a way to secure services so that those are not generally available to whole world. Problem then was the fact that connecting ADF to blob in a VNET was not possible without provisioning a virtual machine inside same VNET and installing a self-hosted integration runtime on it. We were building our solution in a serverless way so installing one didn’t sound like a great option.
Last fall things changed when Microsoft finally published a solution for connecting ADF into a storage account attached to a VNET. Now let’s see how it works!
For this demo I provisioned a Data Factory and two storage accounts:
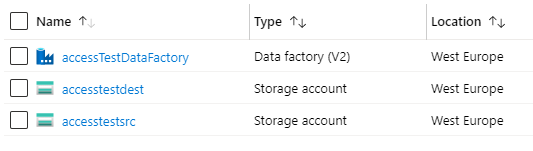
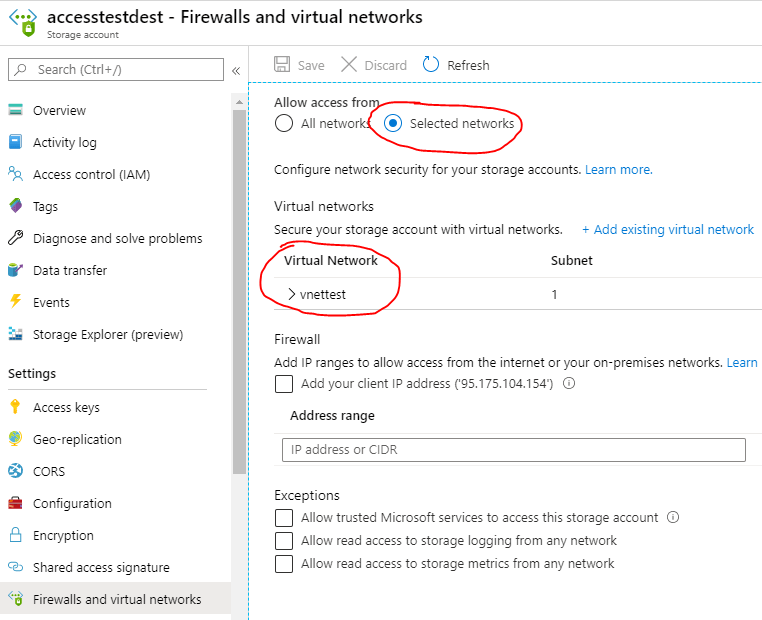
Scenario is to copy a file from accestestsrc to accesstestdest. Source blob is public but destination is secured using VNET. Here’s how destination storage has been attached to a VNET so it is not accessible from everywhere:
Now let’s build a pipeline in Data Factory side to copy data from source to destination. While doing this, things go south when configuring destination sink:
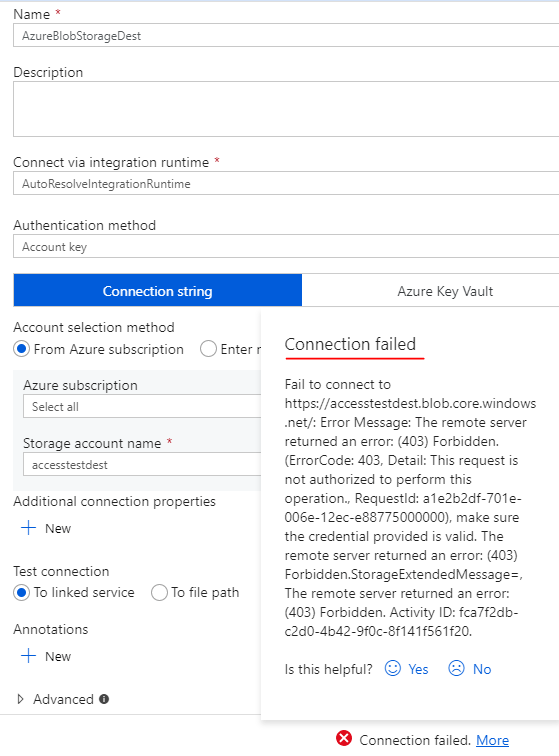
Error 403 is thrown because ADF cannot connect to storage account because blob is connected to a VNET and ADF is not. To make connection happen we have to configure three things:
- Add ADF’s managed identity into Storage accounts with proper access rights
- Enable ‘Trusted Microsoft services’ setting on storage properties
- Change authentication method from account key to managed identity
First one is done in storage account settings. Let’s select Access control (IAM) -> Add -> Add role assignment. For a Role we select ‘Storage Blob Data Contributor’ and then then name of our Data Factory (accessTestDataFactory) is written into ‘Select’ textbox. A query is done and our ADF will be listed below. Then we just select it and hit Save button.
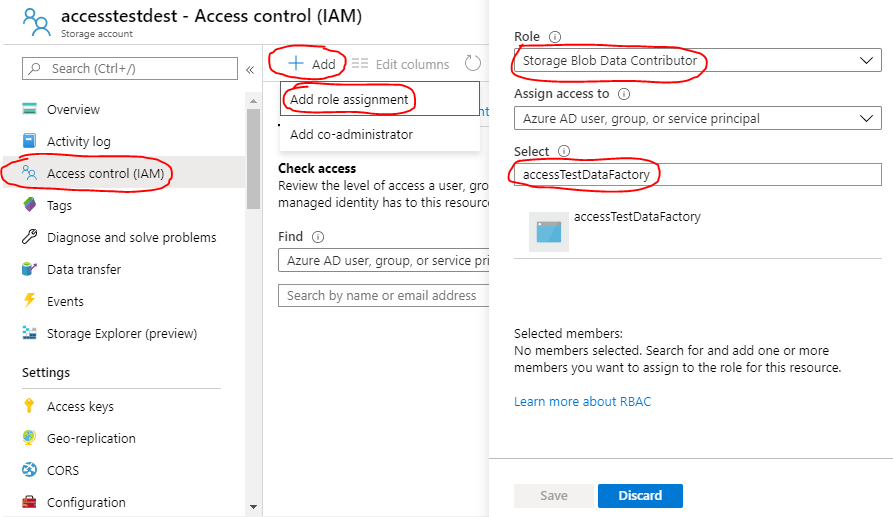
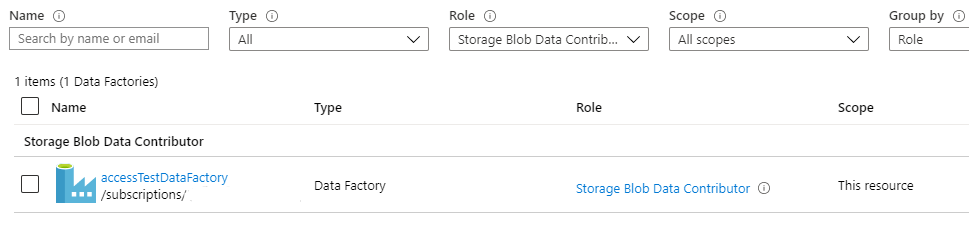
Now our Data Factory is listed in assigned roles section:
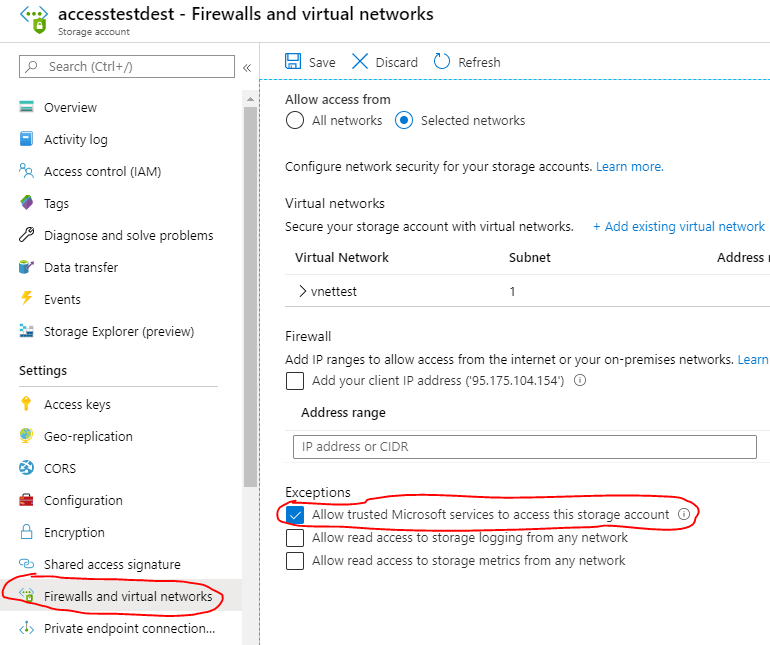
Second part is done in Firewalls and virtual networks section. Select ‘Allow trusted Microsoft services to access this storage account’ and hit Save button. Azure Data Factory nowadays belongs to this set of Azure services which it wasn’t before announcement in fall 2019:
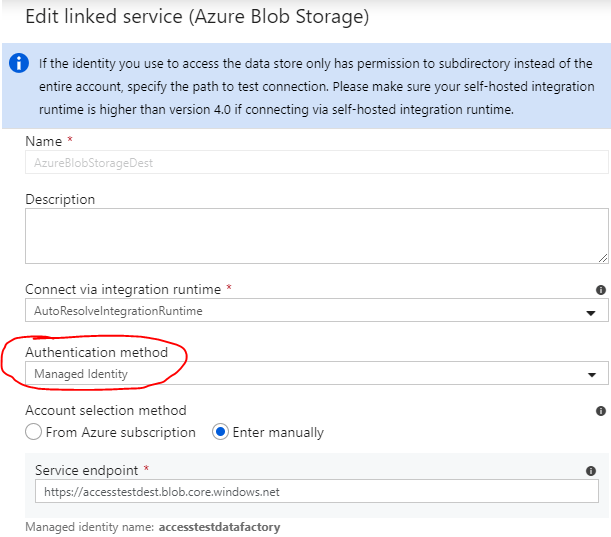
Lastly we have to change authentication method in ADF side: When we initially created connection to blob in ADF, it used account key as a method to authenticate. We must change it to use Managed identity to which we gave access rights to storage in step 1. Let’s edit linked service settings:
Now we are ready to finish and test copy pipeline again. It seems to complete without errors:
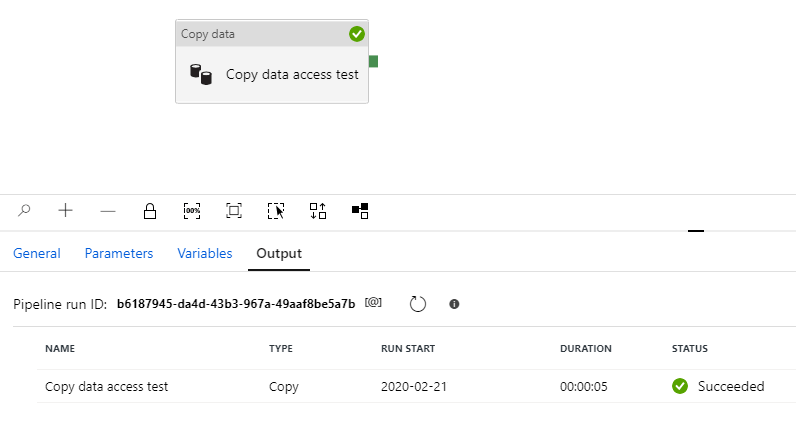
Let’s verify that the file has been actually copied to destination blob using Storage Explorer:
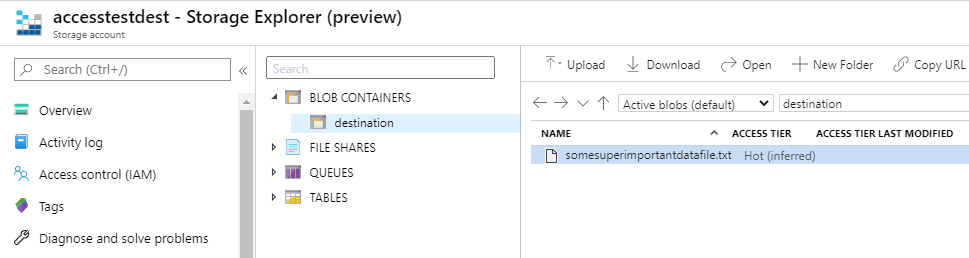
File somesuperimportantdatafile.txt is found in destination also so everything worked as planned.
I really like the simplicity this new feature enables. No more extra VM’s just to make connection happen and much more cleaner architectures. Also cheaper one because the absence of a VM. Go Serverless!

Your a life saver good sir!
LikeLike