I wanted to monitor our electricity usage on more granural timeframe than the monthly bills we are getting. My local provider Lahti Energia has usage statistics available on their website that are on a hourly granularity. It even has some data visualizations built-in but those are kind of basic so I figured I could build something by myself.
It is possible to download data in a csv format but that requires logging into service and manually doing some selections. As a lazy data engineer I want to automate things. Unfortunately there’s no any kind of an API, like REST, available so I had to come up something else: Web scraping. It is a method where web browsing is done programmatically to get the data needed. It’s far from ideal because even a tiny change in web page can break the procedure. But since there wasn’t API available, scraping was the way forward.
I had Raspberry Pi up and running so I figured a Python script could do the heavy liftin’n’shiftin. Python also has lots of good libraries for doing screen scraping, connecting Azure etc.
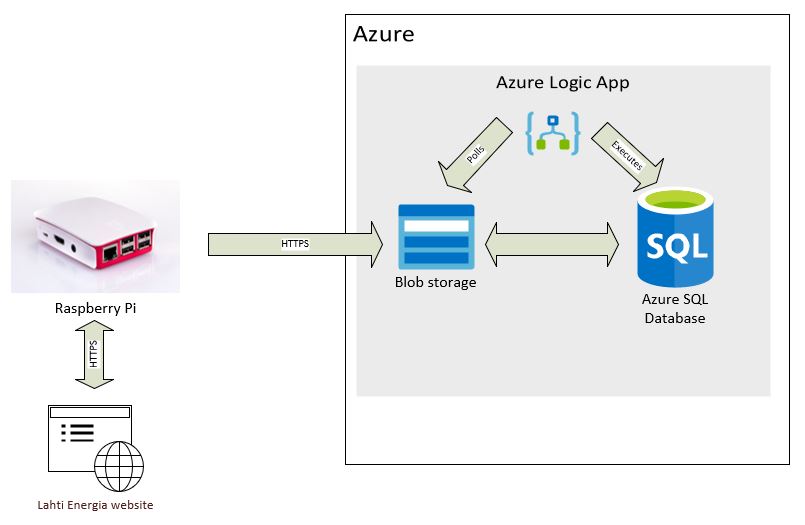
I wanted to utilize cloud services as much as possible because I like the concept of someone else taking care of the platform. So I decided to place the data into a relational cloud database: Azure SQL DB. I already had one running so it was only a matter of creating a couple of database objects. I also like to minimize the amount of code and that’s why utilizing Azure Logic App to orchestrate whole thing seemed to be a right choice.
The architecture I came up is as follows:
- Python script running on my Raspberry Pi scrapes the electricity usage data from my local provider’s web site.
- Script parses data into tabular format (good old csv) and places the file into a specific Azure blob storage container. Script is scheduled using cron.
- Azure Logic app is setup so that it polls blob storage container for new files. When a new file is found, it kicks up a stored procedure found from Azure SQL DB which imports the file into a staging table and from there all new rows are inserted into actual table.
For doing screen scraping against website that requires login, I followed this handy tutorial: https://kazuar.github.io/scraping-tutorial/. Also a big shout out to stackoverflow.com for providing lots of good code examples e.g. how to connect Azure storage, convert UNIX epoch time to timestamp etc.
Microsoft has lots of Python modules for managing Azure services and I’m utilizing those to connect Storage account. I already had a storage account so it was just a matter of creating a new container on it and getting a connection string. A parameter connection_string is a pointer to a storage account and it can be found from Azure Portal -> Storage account -> Access keys -> Connection string.
Actual usage data can be found from web page source from a line which begins with a string ‘var model =’. Value is a JSON object but not actually a valid one. This is parsed to tabular format with two column: Timestamp and consumption.
Here’s the code I ended up using:
import requests
import csv
from lxml import html
from datetime import datetime, timezone
from azure.storage.blob import BlobServiceClient
connection_string = "DefaultEndpointsProtocol=https;AccountName=...
# Create the BlobServiceClient object which will be used to create a container client
blob_service_client = BlobServiceClient.from_connection_string(connection_string)
# Create a blob client using the local file name as the name for the blob
blob_client = blob_service_client.get_blob_client(container='sahko', blob='inputdata.csv')
USERNAME = ""
PASSWORD = ""
LOGIN_URL = "https://online.lahtienergia.fi/eServices/Online/Login"
URL = "https://online.lahtienergia.fi/Reporting/CustomerConsumption?loadLastMonthData=true"
def main():
session_requests = requests.session()
# Get login csrf token
result = session_requests.get(LOGIN_URL)
tree = html.fromstring(result.text)
authenticity_token = list(set(tree.xpath("//input[@name='__RequestVerificationToken']/@value")))[0]
# Create payload
payload = {
"username": USERNAME,
"password": PASSWORD,
"__RequestVerificationToken": authenticity_token
}
# Perform login
result = session_requests.post(LOGIN_URL, data = payload, headers = dict(referer = LOGIN_URL))
#print(result.content)
# Scrape url
result = session_requests.get(URL, headers = dict(referer = URL))
formatted_output = result.text.replace('\\r\\n', '\n')
for line in formatted_output.splitlines():
if line.lstrip()[0:11] == 'var model =':
jsonni = line.lstrip()[12:-1]
start = jsonni.find('[[')
end = jsonni.find(']]')
jsonni = jsonni[start+1:end+1]
jsonni = jsonni.replace('],[','\n')
jsonni = jsonni.replace(']','')
jsonni = jsonni.replace('[','')
with open('usagedata.csv', 'w', newline='') as file:
writer = csv.writer(file, delimiter=';') # Let's also write data into file
output = 'timestamp;consumption\n' # header for csv-file
for line in jsonni.splitlines():
start = line.find(',')
epoc = line[0:start]
measure = line[start+1:]
timestamp = int(epoc)/1000
timedate = datetime.fromtimestamp(timestamp, timezone.utc)
timestamp_str = str(timedate)[:-6]
writer.writerow([timestamp_str, measure])
output += timestamp_str + ';' + measure + '\n'
blob_client.upload_blob(output,overwrite=True)
if __name__ == '__main__':
main()
The csv file is given a name inputdata.csv and is placed into a container named sahko. It has two columns separated by a semicolon: timestamp and comsumption which tells the electricity consumption during that hour:
timestamp;consumption
2019-12-04 00:00:00;0.3
2019-12-04 01:00:00;0.06
2019-12-04 02:00:00;0.29
2019-12-04 03:00:00;0.06
2019-12-04 04:00:00;0.24
2019-12-04 05:00:00;0.12
2019-12-04 06:00:00;0.23
2019-12-04 07:00:00;0.23
2019-12-04 08:00:00;0.21
2019-12-04 09:00:00;0.3
2019-12-04 10:00:00;0.07
2019-12-04 11:00:00;0.31
2019-12-04 12:00:00;0.06
Now we have raw data stored in blob! To get the csv file from blob to SQL, these two services must be connected. First a shared access signature (SAS) to blob needs to be created. After SAS being created, following commands are being run in Azure SQL DB:
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '...';
CREATE DATABASE SCOPED CREDENTIAL MyCredentials WITH IDENTITY = 'SHARED ACCESS SIGNATURE',SECRET = 'st=...';
CREATE EXTERNAL DATA SOURCE MyAzureStorage WITH (
TYPE = BLOB_STORAGE,
LOCATION = 'https://<storage_account_name>.blob.core.windows.net',
CREDENTIAL = MyCredentials
);
First command creates a master encryption key. Choose a strong password. After this a stored credentials can be made which utilizes the shared access signature created earlier. Lastly an actual external data source can be created utilizing these stored credentials to connect storage. To verify the connection, following SQL query can be run:

Now the Azure SQL DB is successfully connected into storage! Now let’s create a stored procedure dbo.sp_insert_data for loading csv file into a database table:
CREATE PROCEDURE [dbo].[sp_insert_data]
AS
BEGIN
TRUNCATE TABLE [dbo].[stg_sahko];
BULK INSERT [dbo].[stg_sahko]
FROM 'sahko/inputdata.csv'
WITH (DATA_SOURCE = 'MyAzureStorage',
FIELDTERMINATOR = ';',
ROWTERMINATOR = '0x0a', --LF
FIRSTROW = 2);
INSERT usage(pvm, usage)
SELECT CAST(s.[pvm] AS DATETIME) AS pvm
,CAST(s.[usage] AS NUMERIC(10,2)) AS usage
FROM stg_sahko s LEFT JOIN usage u ON s.pvm=u.pvm
WHERE u.pvm IS NULL;
END
GO
The logic goes so that first a temporary staging table (dbo.stg_sahko) is emptied by running a truncate command. Then raw data from csv file is loaded into this table. We have to tell a little bit of metadata (field terminator character, row terminator and first row) so that the database engine knows how to load file correctly. From staging table only new rows are loaded into actual destination table (dbo.usage) and also the fields are casted into real datatypes (datetime & numeric).
Now we have methods for both generating a csv file and loading that into database. Now we just have to combine there two so that when csv file is placed into blob, it will be loaded into database. For this I’m utilizing Azure Logic app which is a service for automating and orchestrating data flows, processes etc.
Azure Logic app acts like an orhestrator: It polls the specific container (sahko) in blob storage and if there’s new file added (or modified), it fires stored procedure located in SQL to load data into table. Here’s the workflow:
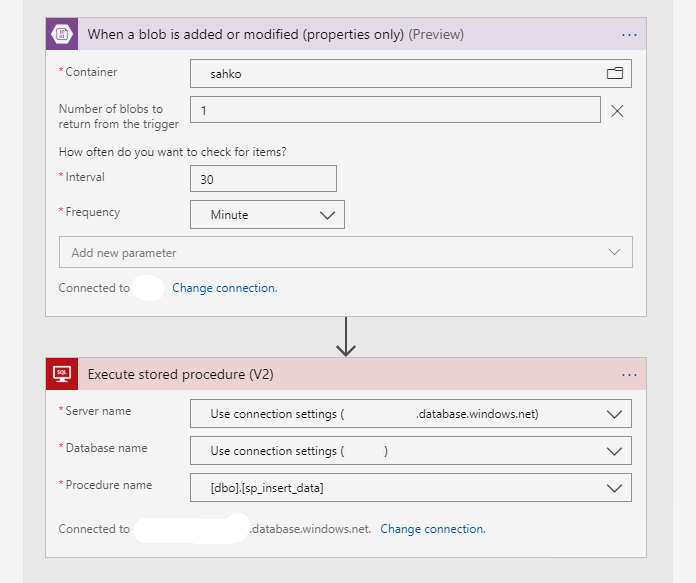
Python script runs once a day at 10 am and pushes the csv file into blob. Even though the website data has a granularity of one hour, it is only updated once a day so there’s no point running script more than once a day.
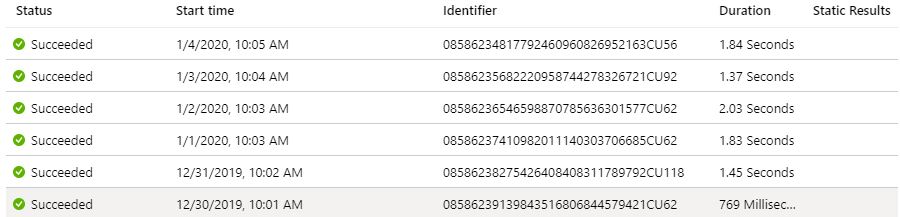
Here’s a screen shot of Logic App logs which shows that the stored procedure has been run couple minutes after csv file has landed into blob container:
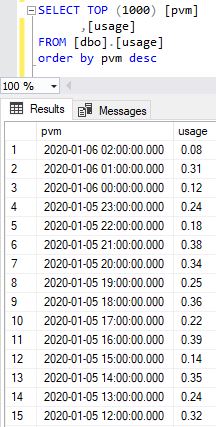
Here’s a screenshot of actual target table in SQL:
And that’s it folks! I’ve shown how to automate data gathering utilizing modern cloud services. I didn’t touch the area of data analysis at all but let’s see if we are able to do that on following posts.
